Latest chrome pushes this up to 132 with uBlock origin off, same hardware, same everything.
Also @jsnell I am still waiting for your response to “there’s no improvement in desktop CPU speeds” based on our actual data from running our Ruby unit tests in Discourse:
I’m not planning on engaging with you further in any CPU-related threads, but will make an exception this once since you pinged me. Your style of argumentation is to mostly ignore anything other people write, fabricate facts, and intentionally sidetrack the discussion at every opportunity when it becomes obvious that you’re wrong about something. It’s a totally fruitless endeavor.
You’re a real piece of work. That’s not a comparison of a 2013 desktop cpu to a similar class 2015 desktop cpu. It’s a comparison of a 2012 (lie 1) low-power server cpu (lie 2) to a 2015 overclock-ricer CPU. I honestly don’t know if you’re trolling for a reaction, intentionally lying and thinking nobody notices, or actually believe what you say. But it’s an equally pointless discussion either way.
Now, in addition to the outright lies, there are some other problems. There is no description at all of the benchmark methodology, no attempt at an analysis of the workloads, and the two CPUs are running with substantially different peripherals (ECC vs non-ECC; SSDs that might as well be from different planets). How is anyone but you supposed to know how to interpret those numbers?
I’m sure it was a great way of benchmarking low-end servers for the specific workload of a small business. It’s not the way you design or run a general purpose benchmark.
The general trend for Intel’s single-thread performance increases since Sandy Bridge has been around 10% per year, across a range of professionally run benchmarks. (There are of course some exceptions, like programs that can take advantage of AVX2). Are you happy with <10% year? Because it sure has seemed like you’re awfully upset when some other companies show speed increases like that.
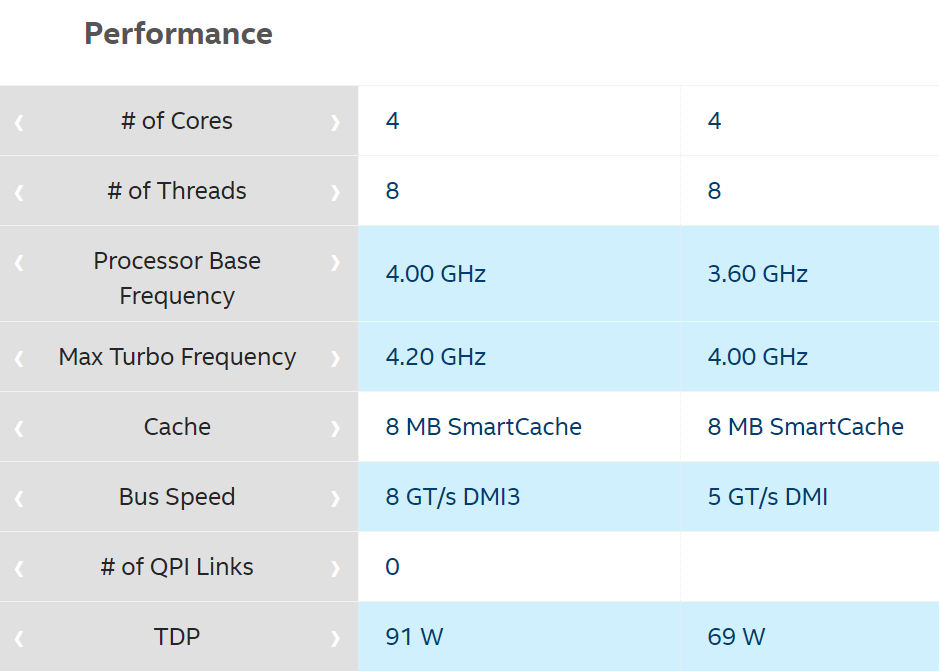
Incorrect, that’s a 3.6 / 4.0 Ghz turbo CPU. See for yourself. It is literally the fastest Xeon you could buy at the time. Again. Don’t take my word for it. Look it up. I dare you. I triple dog dare you, sir.
Here’s a side by side to help refresh your mind grapes:
Samsung 830 and 840 pro are from “different planets”? I agree the 840 is fair bit faster, but it’s not material to the benchmark, which is ruby unit tests and primarily CPU limited. Let’s refer to someone else who downloaded the free open source code (see below) and ran our ruby unit tests on a really slow drive to see what would happen:
Ok, so I wanted to check if the tests were IO bound:
pcie ssd: Finished in 6 minutes 18 seconds
fast microSD drive: Finished in 7 minutes 52 seconds
Clearly IO is not a real issue since the microSD card is orders of magnitude slower than the pcie SSD which would translate in reality to a delta of seconds between let’s say the 830/840 and the 850.
Hey, look at that. I agree it’s sensible to consider, but the post I referenced already had the data you needed. You just didn’t look. Which is kind of an ongoing theme here.
Yet again, incorrect. Go to github. Download the 100% free open source project code. Run the Ruby unit tests. Literally anyone in the world could do this right now, today. Hell, somebody called me out in that 2015 topic then ran the benchmarks himself and then acknowledged he was wrong. Here’s a screenshot of his post:
Read the data. And learn. Turns out, desktop CPUs got substantially faster between 2013 and 2015. As in nearly 2x as fast in some workloads, like ours.
If that fact makes you unhappy or uncomfortable, or disagrees with the “desktop CPUs just aren’t getting any faster these days” narrative you prefer, I’m sorry to hear that. But it’s the truth.
server: Xeon hrm, that doesn’t seem like a lie.
not 2013: Q2’12 hrm, that doesn’t seem like a lie.
low power: TDP 69W hrm, that doesn’t seem like a lie.
It’s like there existed, in 2013, a similar class of chip that you are pretending doesn’t exit:
Processor Number i7-4960X
Launch Date Q3’13
TDP 130 W
Allow me to clarify my statement: fastest single socket Xeon E3 CPU you could buy. Also, 4.0 Ghz is not greater than 4.0 Ghz last time I checked. Let me help you out a little here.
Technically there was a Xeon you could buy that was 4.1 Ghz in the same Ivy Bridge Xeon E3 family, so you could have pointed that out, if we want to quibble over 100 Mhz. But higher end E5 and E7 Xeons are all about m0ar corezzz not higher clock rate. Which doesn’t really help our Ruby code that much, except in terms of more parallel web requests at the same time, but… y’know, individually slower.
It’s true for my enterprise because I understand how to benchmark our Ruby and JavaScript workloads.
So, um, don’t project your businesses decisions on the entire industry. I literally cannot think of a single infrastructure refresh I have been involved in for the last decade where the customer opted for the highest clocked CPU on the market. That’s not to say it does not happen, but it is without doubt the exception unless the project or a particular use case within has very specific requirements.
That would be easier not to do, if JavaScript wasn’t dominating the entire world for the forseeable future… on client and server, ad infinitum.
Good luck putting that particular genie back in the bottle, my friend. It ain’t happening. As a general rule, what is good for JavaScript is best for everyone in terms of performance on everyday computing devices, forever. The relevant sentence you want is this one:
The vast majority of average computing tasks are limited by single-threaded performance
a) his point and mine is you are comparing a fucking xeon with a desktop K chip for no reason other than the fact that you are an idiot.
b)
the E3-1280 V2 has a passmark of 9561
the i7-4960X has a passmark of 13833
There is absolutely no reason you are comparing the i7-7700k to a Xeon from the wrong year instead of the i7-4960X from the right year except it fits your goalpost shuffle.
I don’t really care to put any genies back in any bottles. Javascript will be what it will be until it isn’t when the next platform comes along.
But seriously, take step back, the decisions you make in your business are not representative of the market as a whole. I know you are super into tech and want your platforms to operate as performantly as possible and also own the commercials to make that possible, but you need to stop assuming every other business out there is the same. You are an exception in that regard.
Go ask Amazon if they pay a premium for the highest clocked CPUs at any given time, because I bet dollars to donuts they don’t - they buy whatever is the lowest $:Ghz they can get at any given time. They may care mostly about balancing/optimising the commercials of Ghz:Mem:IO:bandwidth across a POP, but GHz is rarely going to be the limiting factor.
I hate to be the one to break this to you, but … Xeon E3s are nothing special. They’re more or less identical to Intel Core i7 chips (of a given generation), except
Xeons support ECC.
Xeons are clocked a bit lower because conservatism. A fair limitation for 1U though, I’ve put 150+w TDP CPUs in a 1U server chassis and it’s … not pleasant.
Xeons tend to have much higher hard-coded memory limits, but not the E3.
Xeons sometimes don’t have on-die GPUs, because those are less useful on servers, though it depends.
See for yourself on the i7-6700k versus its Xeon E3 equivalent. Same CPU, same cache, same number of cores/threads, etc. Hell even the maximum memory limit is the same at 64GB, which is a real kick in the ass. Don’t take my word for it. Click the link. Read the actual data sheets, the comparison is side by side. Xeon E3 is nothing more than a Core i7 with enterprisey marketing sauce (and naturally, extra enterprisey price) added.
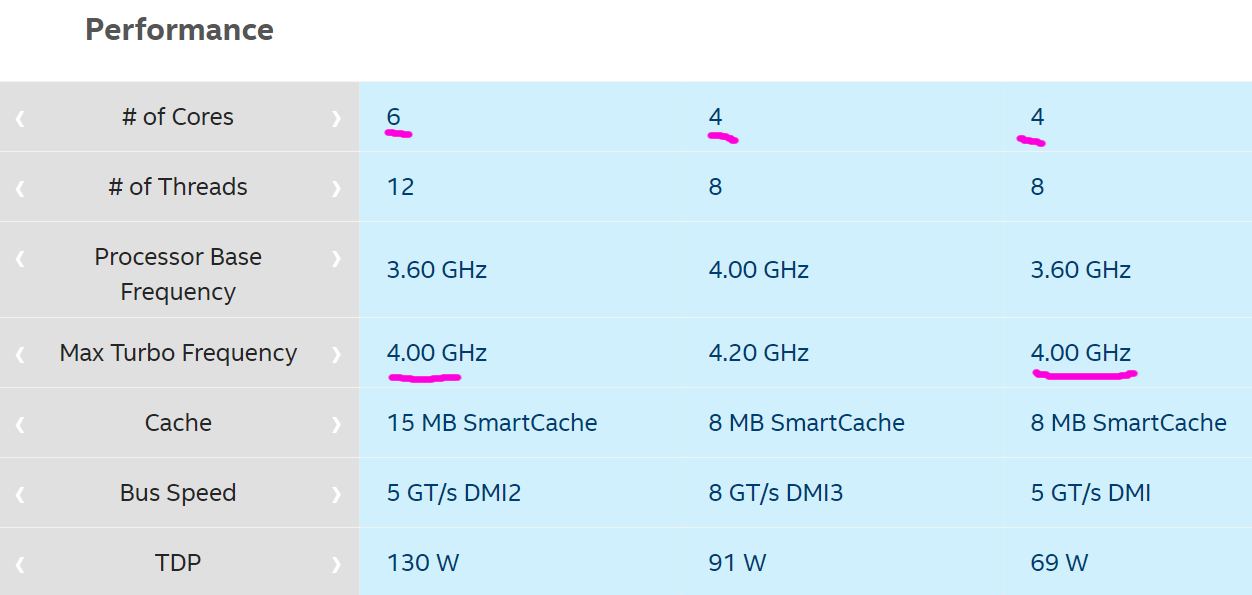
So yeah, a Xeon E3 and Core i7 are in fact almost identical, minus a tiny bit of clock speed. Look closer:
The highest a skylake Xeon E3 (v6) gets to is 4.2 Ghz, whereas the Kaby Lake Core i7-7700k goes to 4.5 Ghz.
The Xeon E5 and E7 can be far more exotic, but that’s mostly in terms of number of cores on the die, plus they support multiple CPUs on the same motherboard, which the E3s absolutely do not. The fancier Xeon E7s can command close to $10k per die for the 24+ core monsters. And the arbitrary RAM limit is lifted – there is more memory bandwidth for connecting tons of RAM in parallel – 128gb, 256gb, 512gb, 1tb… stuff you literally can’t even do on the Core i7 or the Xeon E3 because the maximum memory is hard coded to 64gb*.
* as of Skylake. Before Skylake, the max RAM on a Core i-anything and the Xeon E3-anything was 32gb. And that sucked.
Partially true; they optimize for more cores versus clockrate because you can’t slap 24 different 4.5 Ghz cores on a die without stuff melting down. Here’s the broadwell (Xeon E5 v4) series, for example:
Someone points out how wumpus has made a cherry picked argument with applicable benchmark.
Wumpus deflects by a huge set of links that make up a fake argument so he can pretend that he never made his earlier claim.
I do have to admit that the fact that he was willing to cherry pick 2 entirely different chips to compare was bold.
Anyways:
I agree that two very similar chips that you have cherry picked which are not the chips we discussed above are similar. In particular if you make a bullet point list of their differences and discount them, but even with that aside those two specific chips are similar.
And look, those two chips perform similarly:
6700k Passmark 11113
E3-1280 v5 Passmark 10666
Pretending that I or others have made an argument that they are not is classic derailing.
I would quibble with the idea that traditional values guide the clock speed but this isn’t P&R.
Show me a single time I have called anyone a liar. I may have said people were incorrect when they, in fact, were incorrect. I don’t call people liars. I just point to data. If you don’t like the data, my apologies.
You could unleash a thousand core CPU at the ruby unit tests in the Discourse project (which, again, is freely downloadable open source code that anyone can run on their own machine) and they won’t be finishing one bit faster. Perhaps that is your misunderstanding?
(You could argue, “hey Jeff, why don’t you split up the unit tests on your project so 1/6 of them run on 6 different CPUs?” and that’s valid. Not exactly trivial, which is why we haven’t done it. Which may also answer your implicit “Why isn’t all the code in the world magically scaling perfectly across a zillion CPUs? Is it because you are terrible programmers?” question*, but it doesn’t mean any individual test will get done any faster, of course.)
These CPUs were not “cherry picked”. These are the actual CPUs that were actually in the servers we use:
And then someone said “oh noes! Xeon not the same as Core i7! YOU BAD MAN! YOU VERY VERY BAD MAN!”
That’s why I wrote an entire post in quite some detail to explain why that is, in fact, a valid comparison, because a Xeon E3 is literally a Core i7, yes indeed a tiny bit slower in clock rate, with ECC memory support and a few other meaningless differences.