Maybe you should watch this documentary: https://www.youtube.com/watch?v=NuGT_L13bQ8
crowdsourced chess!!
I’m liking all the enthusiasm! @JoshL, I watched that trailer – looks really fun!
Yep, but this only gets you so far – maybe the first dozen moves or so, if that. If the human player deviates from the standard opening dance, then the computer has to “think” for itself. As for gambits, those are mostly varieties of openings; queen’s gambit declined, say, offers a pawn at the start, and the other player declines it. It’s true there are set endgame patterns one also learns as a player. When I was a kid my dad taught me queen-and-king and rook-and-king, the two easy ones. One also learns pawn/king finishes, and computers can too.
Yep, that’s exactly what I’m working on. Pruning is going to be very difficult. I’m going to have my hands full managing all the branches on an unpruned tree, heh.
At this stage my AI is now able to move its pawns, knights, and king. Randomly, heh.
It makes for some funny positions. The AI king actually respects the rules of check, to some extent, so it doesn’t take pieces that are guarded by other pieces. I’m working on ensuring it can’t move into check either. After that, I’ll do the rook (not too hard), the bishop (harder), and queen (not so bad once the bishop and rook are done). I hope to have that work done today so that I can start making the AI smarter tomorrow. I’m thinking I’ll try teaching it one opening, then dive into minmax.
I made Tic Tac Toe in Python (just in-terminal with keyboard prompts for controls, very 1976), which didn’t seem too hard, but checkers was a lot more complex and I didn’t get it 100% finished. Never tried chess, nor did I even attempt AI.
I’m currently pretty excited that I’ve finally managed to implement some kind of A-Star pathfinding on the fly in my retro CRPG NPCs. Now if only I had more than an hour a week to work on it…
It’s not chess, but I maintain an engine for the hnefatafl games, which I’ve had a fascination with for some time. Pruning and depth of search are the most important factors in a classical board game AI, in my experience.
I cribbed heavily from a series of blog posts about a chess engine written in Java as a learning exercise, but I’m having a hard time finding it now.
I wrote a checkers game a couple decades ago and didn’t finish it either. Chess is more fun!
Wow, that is extremely cool! I’ve never played that family of games, but they look fun – and plenty complicated to code.
Incidentally, I like that Game Maker Studio 2 provides easy integration with Git and Github. It’s nice having web-based backup even for a solo project.
For now my chess game still qualifies as a “10 minute” game, as my AI is still rudimentary, and I can beat it in about 2 minutes. But it’s getting better! I’ve taught it one variation of the Sicilian Defense, and I’ll teach it more today. More importantly, today I start in earnest the “minmax” AI – the “thinking” the game does when it’s not following a scripted opening. I’m having lots of fun with this.
I look forward to the day when I can purchase it on Steam!
lol, don’t open your wallet just yet. :)
I’'m making progress. The AI now takes the most valuable piece it can, which is not great chess but an improvement over a pure random AI. Now I’m implementing piece-square boards for all the pieces – weighted scores for each spot on the board to encourage the AI to avoid the sides and corners in the early and mid-game. After that, I’ll implement the second level of search – the algorithm seeking to minimize the human’s response to the AI’s proposed move.
So right now I’m thinking minimax, rather than Negamax, which puts a negative sign in front of the “minimize” score assigned to the human’s response, so that one is always dealing with the same score-scale. I may try to implement Negamax if it doesn’t confuse me too much. Either way, I will eventually alpha-beta pruning (an algorithm to bypass tree branches that are definitely suboptimal).
I don’t plan to use the Monte Carlo tree search (MCTS), which has the AI play out thousands of games to conclusion using random moves! It then adds up which games are winners and which are losers, then choose a move based on that data. That sounds awesome, especially since my AI is already exceptionally good at random moves. :) But even experts have trouble applying MCTS to chess; it’s something I’d like to experiment with in a different game.
If anyone has thoughts on all this, I’m all ears.
Piece-square tables make a big difference to an AI’s sense of position and control there…over.
In terms of innovations over pure minimax that made my tafl AI better, they go in about this order:
- Alpha-beta pruning. You search orders of magnitude fewer nodes for a given depth. Note, however, that the efficiency of A/B pruning depends on the applicability of your evaluation function. The more your evaluation function diverges from the ideal, the more likely you are to prune branches that are actually promising.
- Zobrist tables. My evaluation function is relatively heavyweight, though, so there are large savings in analyzing positions only once.
- Killer move tables, and move ordering generally. Searching the most promising moves first yields earlier alpha-beta cutoffs, which increases your effective search depth.
- (Dishonorable mention.) The history heuristic (‘this move was good in the past’) actually made my AI play worse, because of the added overhead.
MCTS gets harder the more open your game is. Go fits it well, because every game ends after a few hundred moves, tops. It’s much less clear how to make your ‘random’ playouts approach the end of the game in chess. (Tafl may be a middle ground there. I’ve been doing some work on a Monte Carlo AI, but haven’t gotten anywhere close to finishing.)
Hey, thanks for that very helpful reply. I had not heard of Zobrist tables, so I’m glad I know of them now. I am vaguely familiar with killer-move tables; I’ll learn more about them.
I’ve now implemented most of my piece-square tables, and the AI is notably smarter – but still rudimentary. I’m almost ready to start implementing minimax.
So I’ve implemented one level of minmax – meaning the AI will now look ahead one whole move, lol. Still, that small change has made a drastic improvement in its intelligence. If I let it play a scripted opening (e.g., Sicilian defense), it gives me a pretty good game until the late midgame. Occasionally it pulls ahead of me in material, as it never makes boneheaded errors, and if I’m tired or lazy I do. But inevitably I get the win, because I haven’t taught it enough about endgames or checkmate.
For now, my plan is to deepen its search pattern to four or five moves ahead, if processing speed permits it. Then I’ll expand on scripted openings for both sides. Then maybe some work on endgame scripts, depending on how much patience I have. At that point I’ll probably declare victory and move on. Already I’m getting depressed at the thought that my own creation may soon be better at chess than I am…
Sounds like some good progress. And I’m curious… Is the AI working in a separate thread? Just curious.
Having you talk about the AI reminded me of back in the day when the Atari 800 computer was just released (fall 1980). There was a wargame called Eastern Front that had been released. I think it was done by Chris Crawford who was a big Atari dev back then, and a smart guy to boot. Back then of course, you would be used to alternating turns with the AI and having the AI take some time to determine its move. So you would move, then the AI would think and then move and so forth. So there would be a little delay during the computers turn while it figured out what it should do.
However, Eastern Front was not like this. When you hit End Turn the AI moved instantly… there was no delay at all. At some point I read an article describing how he accomplished this. The way Crawford implemented the search was to hook a callback routine into the vertical blank interrupt of the TV refresh, so that every time the CRT gun finished drawing a frame, while it was traveling back to the top of the screen to draw the next frame (30 times a second), the AI would do a teeny bit of work planning it’s moves. And whenever the player ended their turn, the AI went with whatever its current best move was. So I assume the longer you sat there on your turn, the longer the AI had to plan its move. It struck me as an ingenious way to Implement the AI.
So when are you going to start working on 3D Chess, Spock?

Of course! Right now I’m stuck with irrational human opponents. Although Captain Kirk’s illogical approach to chess does have its advantages.
That does sound ingenious. I played one of Crawford’s games back in the day – a Battle of the Bulge Game, I think. I enjoyed it a lot, and I remember being embarrassed when I made a silly criticism (about replayability) on a forum somewhere and he responded personally!
I have no idea how to implement thinking while the AI is thinking, or using a separate thread, or any such. I sure could use it! Processing time is now my #1 issue.
I have the minmax algorithm working smoothly: it sees ahead 2-plus moves and now plays as well as me through much ot the midgame. (Only the endgame salvages my pride, and if I have the patience, I’ll give it some endgame scripts to fix that.) It sometimes gets me on the ropes, in fact, but then it lets me off the hook. E.g., just now it seemed to have won my bishop, but it insisted on attacking my queen instead of just taking the prize, and I eventually wriggled away.
Anyway, with even just two moves ahead, it takes 10-30 seconds a move in the early and midgame. It does get quicker in the endgame. And I have not yet implemented alpha-beta pruning, which can drastically cut down on time spent evaluating useless moves. (I want to make sure my minmax is solid first.) Also, I am still churning out a ridiculous number of debug messages to myself, which may be slowing things down. And I have not yet tried compiling an executable that runs directly on Windows, rather than on the Game Maker Virtual Machine. So, lots of stuff to try.
For a while I also had a memory leak, but I think I’ve fixed that now, though I’m still testing. Game Maker Studiio lets you create flexible “list” data structures, which I use to populate my move lists, but you have to be careful to clean them up when done. I’m still not sure I’m doing that optimally.
This is a very fun project, but I’m starting to wonder how far I want to go with it. Do the lessons I’m learning here (minmax, pruning) have any bearing on AI for more complex board states, as in 4X games, wargames, or card games like Hearthstone, say?
Afraid not. The first two are very unlikely to do any lookahead. Heck, they aren’t even going to do an exhaustive search of the moves available to the AI in one ply. There’s just too many combinations of moves available. So it’s all going to be heuristics + scoring functions, and optimizing each unit / city / etc in isolation. Also, the algorithms you’ve learned won’t really work well with randomness, which almost all wargame / 4x systems depend on.
Games like Hearthstone are tricky for another reason. There the state space would probably be manageable, but the problem is all the hidden infomration. You don’t know what cards the opponents has in hand, and you can’t predict which cards you’ll draw the next turn. For this kind of cardgame, you’d probably go with a Monte Carlo Tree Search, neural nets, or a combination of the two (which is the new hotness after AlphaGo).
Wargames / 4X can (and in some cases do) implement some sort of goal oriented planning, where looking ahead is indeed done. You just do it over a very abstracted board state and objectives, instead of exploring all moves you explore all broad strategies and then the moves themselves would just be locally optimized. I think for any GOAP style AI framework the lessons learned could be applied.
Ottomh, I think Armageddon Empires did some sort of goal oriented AI.
Thanks for your replies. That’s more or less what I thought. I’m still glad I’m learning the minmax thing. It’s one thing to read about the algorithm and think it makes sense. It’s another to see how amazing it is in practice. My Minimize and Maximize scripts call each other recursively, passing moves back and forth, assessing them, returning values to each other, storing those values. They’re really my first experiments with recursive functions, to be honest. I’m really a coding newb.
MCTS looks like an exciting algorithm to implement. Some people have even tried it with chess, with mixed results, apparently. I like the idea of applying it to a card game.
That sounds interesting. I could at least imagine min-maxing whether it’s feasible to weaken position x to take position y, and whether the opponent would have a better strategic reply. I wonder whether some limited form of minmax is also feasible on some tactical level. Vic’s AI in “Shadow Empire” certainly seems to anticipate my next move. Maybe this is one advantage of separate spaces for tactical battles, as in Age of Wonders and Planetfall?
4X and wargames are my favorite genres, and yet probably the genres I’m least equipped to code as of now. I’m working my way up!
Now that I’ve made Tetris and made a credible chess AI, what’s a logical next step for someone interested in making strategy games? I’m eager to design something of my own. I’m thinking a deckbuilding cardgame, a la Monster Train / Slay the Spire. Or maybe a simple single-player cardgame with a Hearthstone-like board. Edit: Or just plunge ahead with a little wargame?
For some reason I out my old train game from way back at the start of the thread this weekend, and started doodling around with it.
First, I added proper terrain types with different effects (e.g. mountains slow down trains, swamps are expensive to build through) and made the terrain generator actually generate something that looks nice rather than just random noise:
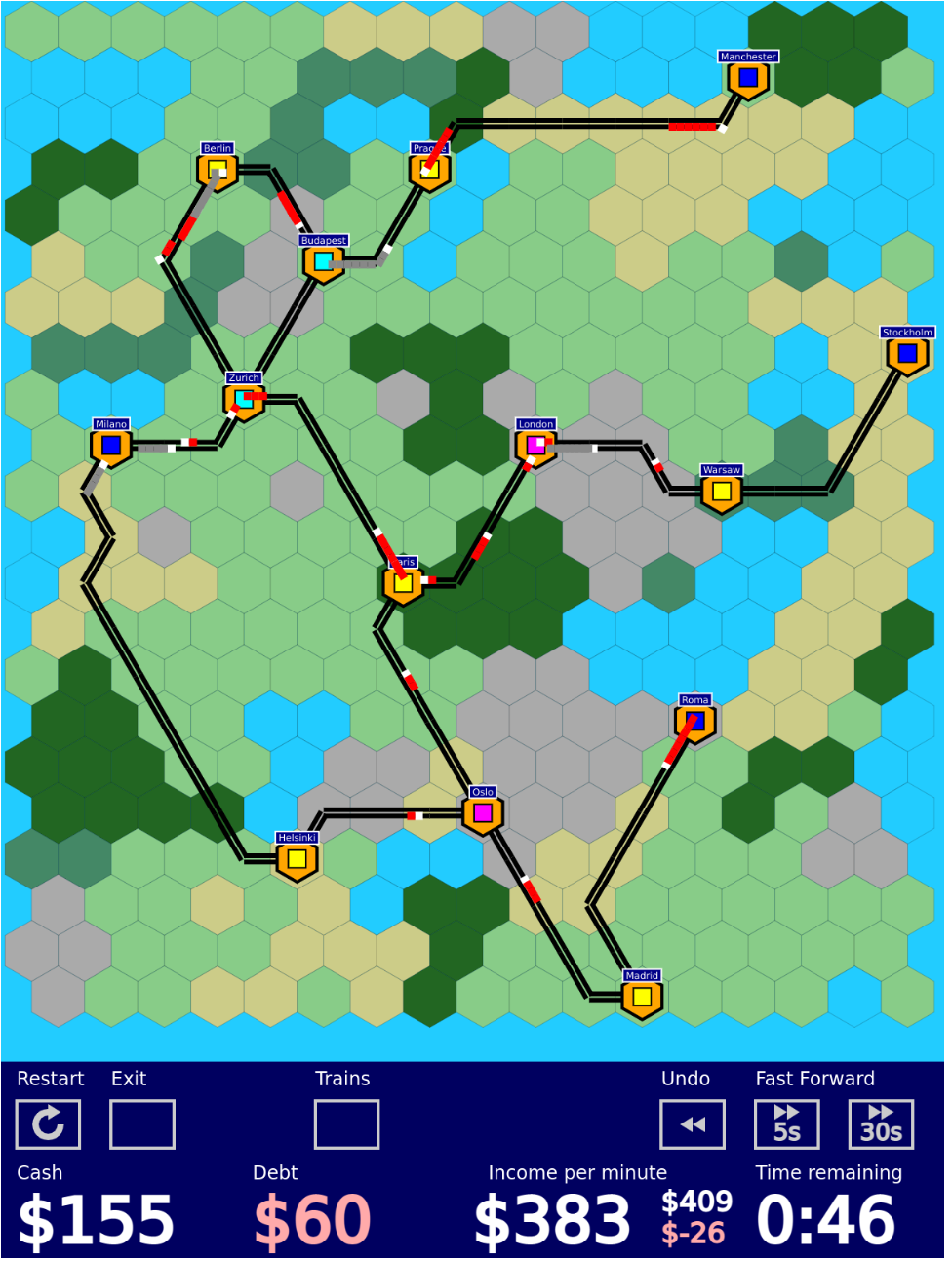
Also, added tooltips for the track building and shipping goods with itemized cost / income breakdowns, to give people who don’t read the manual a chance of understanding the economic system.

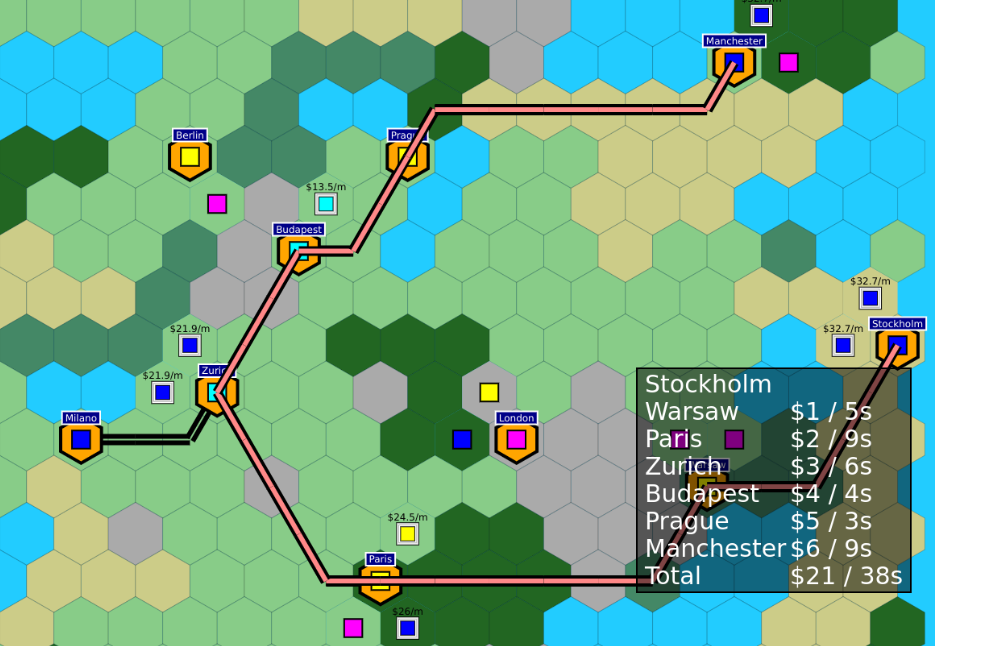
This required also giving cities names, which has a much larger impact on the gamefeel than I expected, just makes it appear way less abstract for no good reason. (And also, might as well show the expected income from each shipment on the map as well rather than force players to read the tooltip.)
There’s also now an undo, which undoes the last action, and again is way more useful than I expected. It’s really nice to just be able to try out a track build and see what the impact of it would be, rather than have to replay the whole scenario. Totally obvious in retrospect, but somehow it didn’t fit the vision when I originally wrote.
And finally, I added an overlay for showing what each of the trains is actually doing, to make it easier to reason about how big the impact of traffic jams is, and also to drive home the point about needing long multi-city shipments.
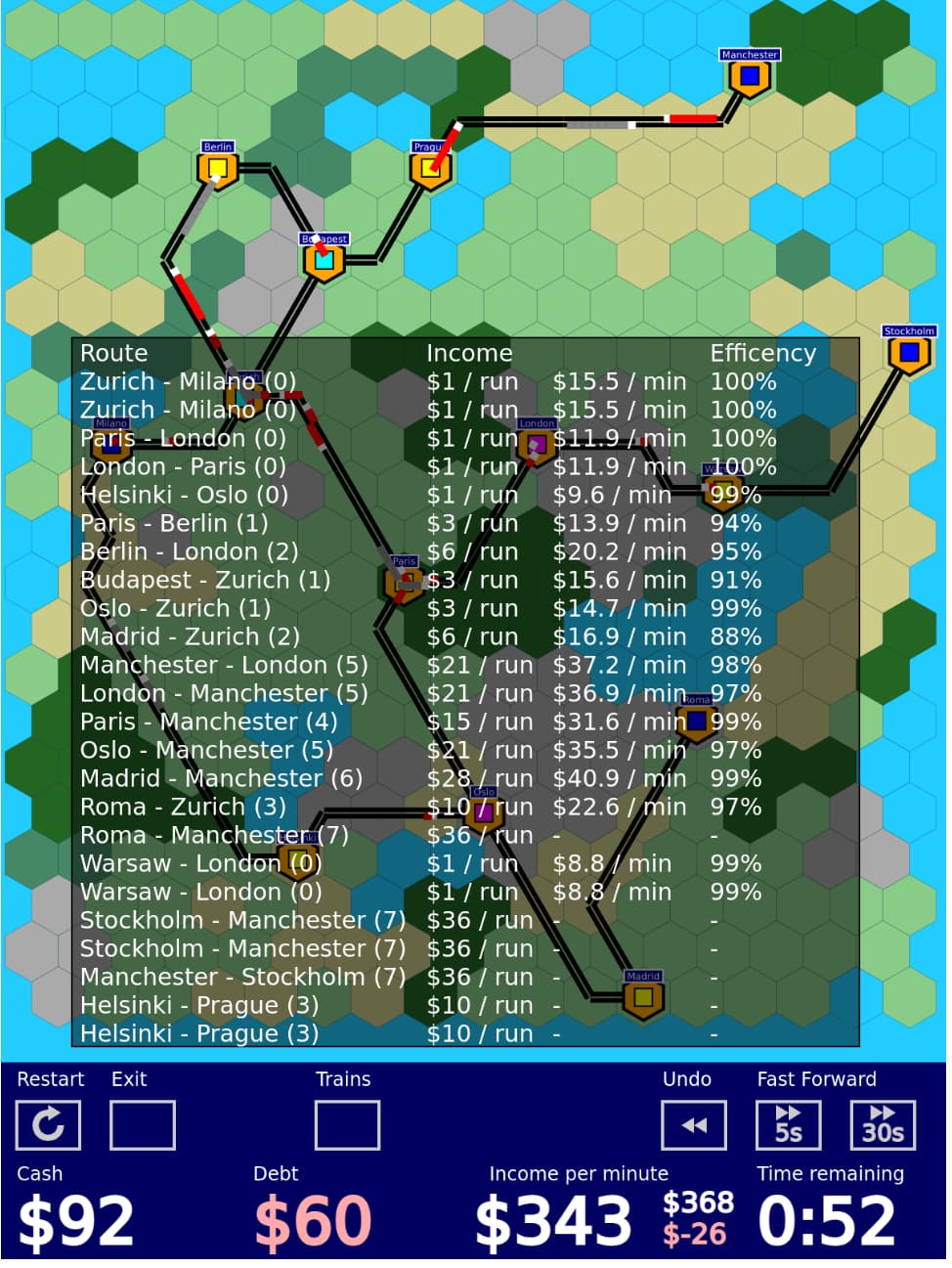
Plans for the next time I work on this:
- Set up special powers (part of the random scenario setup), which change the rules somehow for either the next few actions or the rest of the game (e.g. allow building over water tiles, give an extra $ of revenue for any transit shipping through yellow cities for the next 3 trains, increase train speed through forests, etc). There will be a 2 minute cooldown between purchases. So the goal would be just to add more strategy space around timing/sequencing of the special powers and the map play. (Slipways convinced me that I was being way too much of a purist about making a logistics puzzle game, and special powers will just outright make it more interesting.)
- Add terrain textures, if I can find something that’s not too garish.
- For real implement the original goal of daily/weekly/monthly puzzles with leaderboards.
I’d forgotten how fun it was to have a mostly functioning and playable game, and just do all kinds of little feature additions and polishing. It’s really motivating when every change has an immediate impact, unlike when staring at an empty source code file.
Great stuff! That seems like more than a 10-minute challenge!
What engine or language are you using? And how did you implement your hex grid? I’ve spent many long hours on hex grids. Amit’s hex site helped me, but it’s tricky.